
ImageNet as a Representative Basis for Deriving Generally Effective CNN Architectures
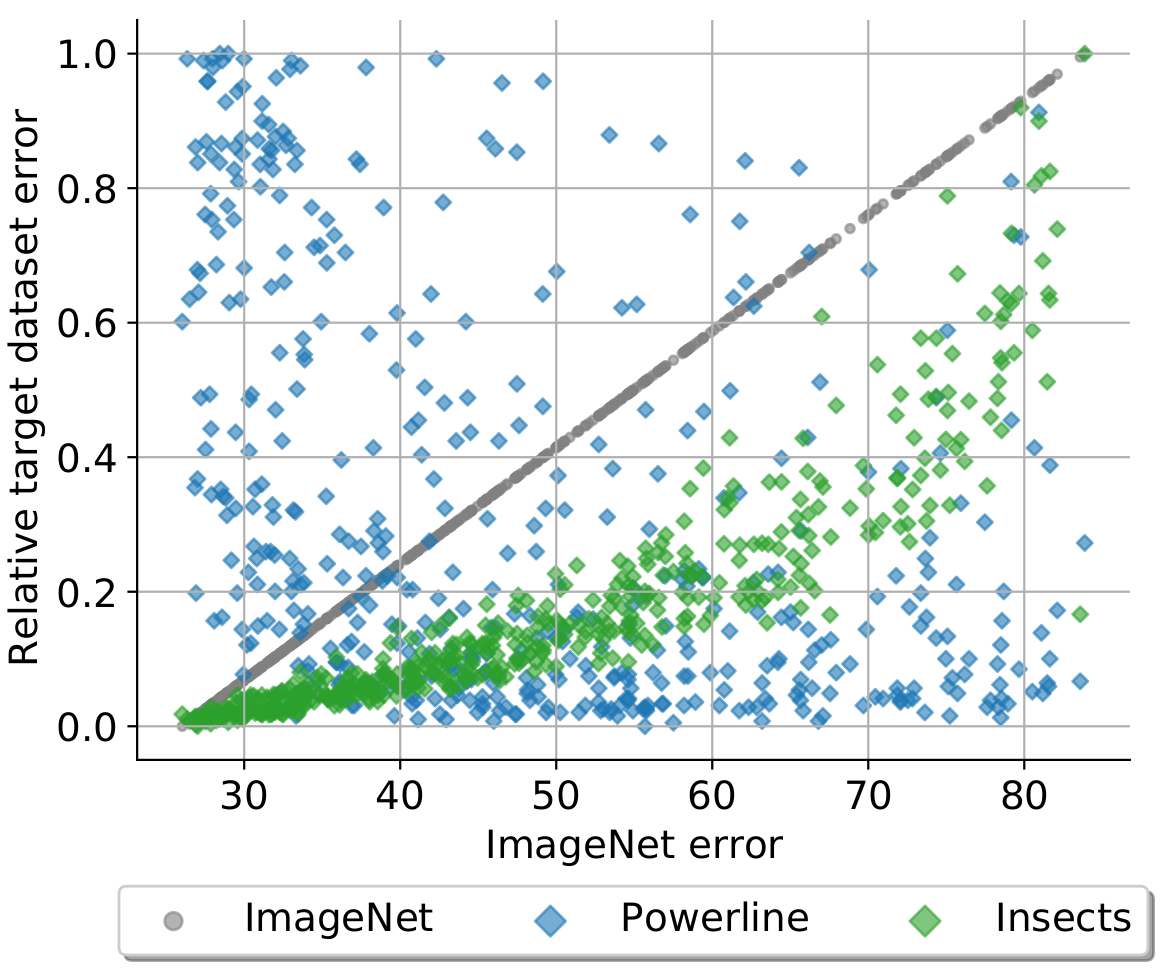 We investigate and improve the representativeness of ImageNet as a basis for deriving generally effective convolutional neural network (CNN) architectures that perform well on a diverse set of datasets and application domains. To this end, we conduct an extensive empirical study for which we train 500 CNN architectures, sampled from the broad AnyNetX design space, on ImageNet as well as 8 other image classification datasets. We observe that the performances of the architectures are highly dataset dependent. Some datasets even exhibit a negative error correlation with ImageNet across all architectures. We show how to significantly increase these correlations by utilizing ImageNet subsets restricted to fewer classes. We also identify the cumulative width across layers as well as the total depth of the network as the most sensitive design parameter with respect to changing datasets.
We investigate and improve the representativeness of ImageNet as a basis for deriving generally effective convolutional neural network (CNN) architectures that perform well on a diverse set of datasets and application domains. To this end, we conduct an extensive empirical study for which we train 500 CNN architectures, sampled from the broad AnyNetX design space, on ImageNet as well as 8 other image classification datasets. We observe that the performances of the architectures are highly dataset dependent. Some datasets even exhibit a negative error correlation with ImageNet across all architectures. We show how to significantly increase these correlations by utilizing ImageNet subsets restricted to fewer classes. We also identify the cumulative width across layers as well as the total depth of the network as the most sensitive design parameter with respect to changing datasets.
Under review at TNNLS
The DeepScoresV2 dataset and benchmark for music object detection
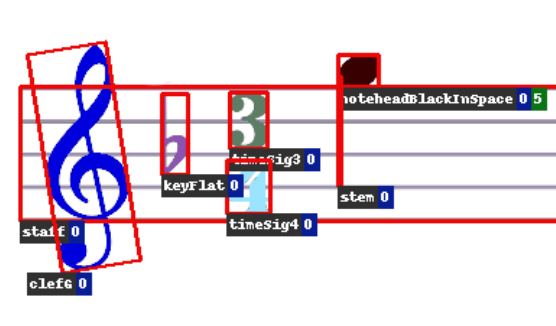 In this paper, we present DeepScoresV2, an extended version of the DeepScores dataset for optical music recognition (OMR). We improve upon the original DeepScores dataset by providing much more detailed annotations, namely (a) annotations for 135 classes including fundamental symbols of non-fixed size and shape, increasing the number of annotated symbols by 23%; (b) oriented bounding boxes; (c) higher-level rhythm and pitch information (onset beat for all symbols and line position for noteheads); and (d) a compatibility mode for easy use in conjunction with the MUSCIMA++ dataset for OMR on handwritten documents. These additions open up the potential for future advancement in OMR research. Additionally, we release two state-of-the-art baselines for DeepScoresV2 based on Faster R-CNN and the Deep Watershed Detector. An analysis of the baselines shows that regular orthogonal bounding boxes are unsuitable for objects which are long, small, and potentially rotated, such as ties and beams, which demonstrates the need for detection algorithms that naturally incorporate object angles.
In this paper, we present DeepScoresV2, an extended version of the DeepScores dataset for optical music recognition (OMR). We improve upon the original DeepScores dataset by providing much more detailed annotations, namely (a) annotations for 135 classes including fundamental symbols of non-fixed size and shape, increasing the number of annotated symbols by 23%; (b) oriented bounding boxes; (c) higher-level rhythm and pitch information (onset beat for all symbols and line position for noteheads); and (d) a compatibility mode for easy use in conjunction with the MUSCIMA++ dataset for OMR on handwritten documents. These additions open up the potential for future advancement in OMR research. Additionally, we release two state-of-the-art baselines for DeepScoresV2 based on Faster R-CNN and the Deep Watershed Detector. An analysis of the baselines shows that regular orthogonal bounding boxes are unsuitable for objects which are long, small, and potentially rotated, such as ties and beams, which demonstrates the need for detection algorithms that naturally incorporate object angles.
Published at ICPR 2020 Preprint
Design Patterns for Resource-Constrained Automated Deep-Learning Methods
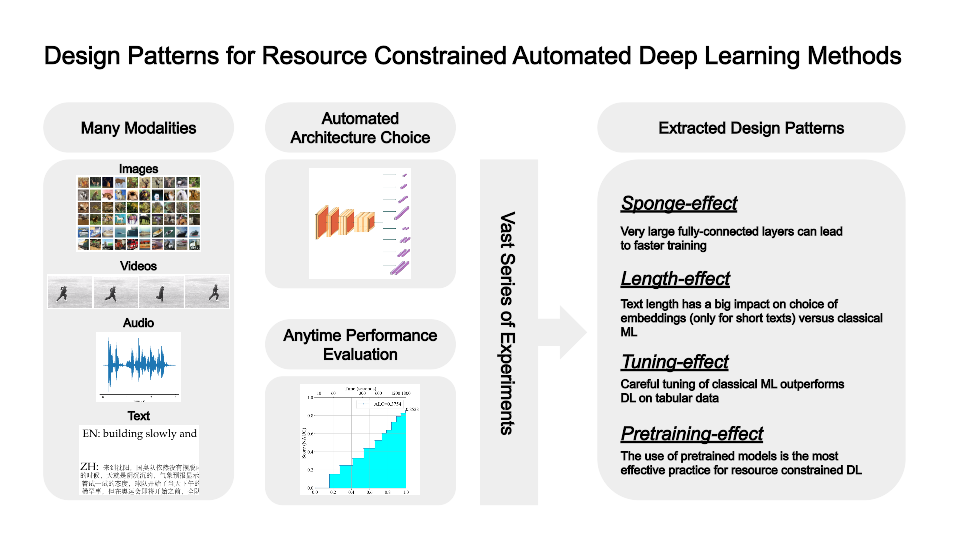 We present an extensive evaluation of a wide variety of promising design patterns for automated deep-learning (AutoDL) methods, organized according to the problem categories of the 2019 AutoDL challenges, which set the task of optimizing both model accuracy and search efficiency under tight time and computing constraints. We propose structured empirical evaluations as the most promising avenue to obtain design principles for deep-learning systems due to the absence of strong theoretical support. From these evaluations, we distill relevant patterns which give rise to neural network design recommendations. In particular, we establish (a) that very wide fully connected layers learn meaningful features faster; we illustrate (b) how the lack of pretraining in audio processing can be compensated by architecture search; we show (c) that in text processing deep-learning-based methods only pull ahead of traditional methods for short text lengths with less than a thousand characters under tight resource limitations; and lastly we present (d) evidence that in very data- and computing-constrained settings, hyperparameter tuning of more traditional machine-learning methods outperforms deep-learning system
We present an extensive evaluation of a wide variety of promising design patterns for automated deep-learning (AutoDL) methods, organized according to the problem categories of the 2019 AutoDL challenges, which set the task of optimizing both model accuracy and search efficiency under tight time and computing constraints. We propose structured empirical evaluations as the most promising avenue to obtain design principles for deep-learning systems due to the absence of strong theoretical support. From these evaluations, we distill relevant patterns which give rise to neural network design recommendations. In particular, we establish (a) that very wide fully connected layers learn meaningful features faster; we illustrate (b) how the lack of pretraining in audio processing can be compensated by architecture search; we show (c) that in text processing deep-learning-based methods only pull ahead of traditional methods for short text lengths with less than a thousand characters under tight resource limitations; and lastly we present (d) evidence that in very data- and computing-constrained settings, hyperparameter tuning of more traditional machine-learning methods outperforms deep-learning system
Published in MDPI AI
Automated Machine Learning in Practice: State of the Art and Recent Results
 A main driver behind the digitization of industry and society is the belief that data-driven model building and decision making can contribute to higher degrees of automation and more informed decisions. Building such models from data often involves the application of some form of machine learning. Thus, there is an ever growing demand in work force with the necessary skill set to do so. This demand has given rise to a new research topic concerned with fitting machine learning models fully automatically-AutoML. This paper gives an overview of the state of the art in AutoML with a focus on practical applicability in a business context, and provides recent benchmark results of the most important AutoML algorithms.
A main driver behind the digitization of industry and society is the belief that data-driven model building and decision making can contribute to higher degrees of automation and more informed decisions. Building such models from data often involves the application of some form of machine learning. Thus, there is an ever growing demand in work force with the necessary skill set to do so. This demand has given rise to a new research topic concerned with fitting machine learning models fully automatically-AutoML. This paper gives an overview of the state of the art in AutoML with a focus on practical applicability in a business context, and provides recent benchmark results of the most important AutoML algorithms.
Published at SDS 2019 Preprint
Deep Watershed Detector for Music Object Recognition
 Optical Music Recognition (OMR) is an important and challenging area within music information retrieval, the accurate detection of music symbols in digital images is a core functionality of any OMR pipeline. In this paper, we introduce a novel object detection method, based on synthetic energy maps and the watershed transform, called Deep Watershed Detector (DWD). Our method is specifically tailored to deal with high resolution images that contain a large number of very small objects and is therefore able to process full pages of written music. We present state-of-the-art detection results of common music symbols and show DWD's ability to work with synthetic scores equally well as with handwritten music.
Optical Music Recognition (OMR) is an important and challenging area within music information retrieval, the accurate detection of music symbols in digital images is a core functionality of any OMR pipeline. In this paper, we introduce a novel object detection method, based on synthetic energy maps and the watershed transform, called Deep Watershed Detector (DWD). Our method is specifically tailored to deal with high resolution images that contain a large number of very small objects and is therefore able to process full pages of written music. We present state-of-the-art detection results of common music symbols and show DWD's ability to work with synthetic scores equally well as with handwritten music.
Published at ISMIR 2018 Preprint
DeepScores and Deep Watershed Detection: current state and open issues
 This paper gives an overview of our current Optical Music Recognition (OMR) research. We recently released the OMR data set DeepScores as well as the object detection method Deep Watershed Detector. We are currently taking some additional steps to improve both of them. Here we summarize current and future efforts, aimed at improving usefulness on real-world tasks and tackling extreme class imbalance.
This paper gives an overview of our current Optical Music Recognition (OMR) research. We recently released the OMR data set DeepScores as well as the object detection method Deep Watershed Detector. We are currently taking some additional steps to improve both of them. Here we summarize current and future efforts, aimed at improving usefulness on real-world tasks and tackling extreme class imbalance.
Published at WoRMS 2018 Preprint
DeepScores – A Dataset for Segmentation, Detection and Classification of Tiny Objects
 We present the DeepScores dataset with the goal of advancing the state-of-the-art in small object recognition by placing the question of object recognition in the context of scene understanding. DeepScores contains high quality images of musical scores, partitioned into $300,000$ sheets of written music that contain symbols of different shapes and sizes. With close to a hundred million small objects, this makes our dataset not only unique, but also the largest public dataset. DeepScores comes with ground truth for object classification, detection and semantic segmentation. DeepScores thus poses a relevant challenge for computer vision in general, and optical music recognition (OMR) research in particular. We present a detailed statistical analysis of the dataset, comparing it with other computer vision datasets like PASCAL VOC, SUN, SVHN, ImageNet, MS-COCO, as well as with other OMR datasets. Finally, we provide baseline performances for object classification, intuition for the inherent difficulty that DeepScores poses to state-of-the-art object detectors like YOLO or R-CNN, and give pointers to future research based on this dataset.
We present the DeepScores dataset with the goal of advancing the state-of-the-art in small object recognition by placing the question of object recognition in the context of scene understanding. DeepScores contains high quality images of musical scores, partitioned into $300,000$ sheets of written music that contain symbols of different shapes and sizes. With close to a hundred million small objects, this makes our dataset not only unique, but also the largest public dataset. DeepScores comes with ground truth for object classification, detection and semantic segmentation. DeepScores thus poses a relevant challenge for computer vision in general, and optical music recognition (OMR) research in particular. We present a detailed statistical analysis of the dataset, comparing it with other computer vision datasets like PASCAL VOC, SUN, SVHN, ImageNet, MS-COCO, as well as with other OMR datasets. Finally, we provide baseline performances for object classification, intuition for the inherent difficulty that DeepScores poses to state-of-the-art object detectors like YOLO or R-CNN, and give pointers to future research based on this dataset.
Published at ICPR 2018 Preprint